Extracting & Mining
Transforming Raw Records into Structured Knowledge
The Art of Extraction
🔄 What is Extracting?
Extracting is the act or practice of taking different records with identifiers and attributes with express intention of joining them together with other records to create a bigger and more comprehensive database in a storage area.
Generally the process of Extracting is followed by loading it into a database or Datawarehouse. Technically this process is referred to as Extract, Transform, and Load (ETL). Depending on data size, type and where the data transformation occurs, there is an alternative process known as Extract, Load and Transform (ELT).
ETL vs ELT Processes
🔄 ETL Process
Extract → Transform → Load
Data is extracted from source systems, transformed and cleaned, then loaded into the target database or data warehouse.
Best for: Structured data, when transformation logic is complex, and when target system has limited processing power.
⚡ ELT Process
Extract → Load → Transform
Data is extracted and loaded directly into the target system, where transformation occurs using the system’s processing power.
Best for: Big data scenarios, cloud data warehouses, and when source data structure is unpredictable.
The Extracting Process
When recording takes place, events, activities, and observations are captured in rows and columns. For instance:
📊 Record Structure Example
Row: Date and time the event took place
Column: Category or type of event related to the date and time
Additional Column: Location where the event happened
Complete Record: “Wedding in London on April 1, 2020 at 2:00 PM”
Identify Records
Locate and select relevant records from various source systems with proper identifiers
Extract Data
Pull records from source systems using appropriate acquisition models (pull or push)
Apply Identifiers
Use unique identifiers to connect related records and create comprehensive datasets
Real-World Application: Ontario Education System
🎓 The Ontario School Information System (OnSIS)
The Ontario data collection system is a prime example of effective extraction at scale. The system collects more than 110 million data records with multiple data points each year.
📚 Data Collection
OnSIS collects data on Students, Schools, educators, and school boards three times per year. Student records include:
- Biographical information
- School enrolment status
- Academic achievement
- Specialized programs
- Discipline incidents
- Language programs
🔗 Extraction Process
All different records are extracted and connected using a unique identifier for each student known as the Ontario Education Number (OEN).
The data is then filtered, transformed, and loaded into the Education Data Warehouse, creating a comprehensive longitudinal view of student journeys.
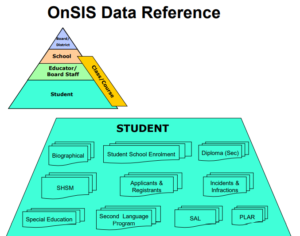
📈 Education Data Extraction Model
Visual representation of how educational records are extracted and integrated using unique identifiers
Education Data Extraction Diagram
(Source: OECD Centre for Education Research and Innovation, 2014)
GHA Extraction Applications
🇪🇹 Ethiopia: Fayda Digital ID
Extraction Challenge: Integrating biometric and demographic data from 28+ million citizens
Solution: Systematic extraction of identity records using unique Fayda Identification Numbers
Impact: Creating Africa’s largest foundational digital identity system
🇷🇼 Rwanda: IoT Climate Data
Extraction Challenge: Collecting real-time environmental data from distributed sensors
Solution: Automated extraction of soil moisture, temperature, and humidity readings
Impact: Enabling data-driven climate resilience and early warning systems
🇰🇪 Kenya: Mobile Money Transactions
Extraction Challenge: Processing 61+ million monthly M-Pesa transactions
Solution: Real-time extraction of financial transaction data for economic analysis
Impact: Powering financial inclusion and economic insights
Technical Implementation
⬅️ Pull Model
Approach: Applications locate and select data sources, pulling data from devices toward themselves.
GHA Example: Scheduled extraction of agricultural data from Rwanda’s IoT sensor network
Advantage: Controlled, scheduled data collection with quality checks
➡️ Push Model
Approach: Source systems notify applications of data availability, pushing updates automatically.
GHA Example: Real-time citizen data updates in Ethiopia’s Fayda system
Advantage: Immediate data availability and reduced latency
🔮 The Future: Federated Extraction
Looking ahead, the GHA region can leverage federated learning approaches where data extraction occurs across decentralized devices (like smartphones) without centralizing raw data. This preserves privacy while enabling collective intelligence from millions of distributed data points.
Extracting: Subtracting from one area (collecting) to add to another area (warehousing) with identifier to make it more
Explaining Extracting:
Extracting is the act or practice of taking different records with identifiers and attributes with express intention of joining them together with other records to create a bigger and more comprehensive database in a storage area. Generally the process of Extracting is followed by loading it into a database or Datawarehouse. Technically this process is referred to as Extract, Transform, and Load (ETL). Depending on data size, type and where the data transformation occurs, there is an alternative process know as Extract, Load and Transform (ELT) (Source: IBM, ELT vs. ETL: What’s the Difference? | IBM). In the case of ELT, the transformation happens after the data is extracted and loaded.
Extracting process:
When recording take place, usually the events, activities, and observations are captured in a row and column. For instance, the day and time the event took place is entered in a row. At the same time, the category or type of event related to the date and time (row), is entered in a column. It may be necessary to add the location or where the event happened. Then we add another column to identify the location (London) where the event (wedding) happened on date and time (April 1, 2020 at 2:00 PM).
Example: Records and System of Extracting Education Data
![]()